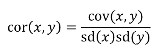Assessing the Genetic Component of a Phenotype
A phenotype is the appearance of an individual, which results from the interaction of the person's genetic makeup and their environment. Phenotypes can be categorical or numerical. If we are interested in the genetic component of a trait there are different methods we can use for analysis.
We define a trait for analysis, determine what we are interested in studying, and then the methods that need to be used. For example, if we want to know how BMI is linked to gene effects we would need to consider other factors such as age, sex, smoking, etc. Thus, a Multiple Linear Regression might be appropriate, were we can measure the variability of each factor.
Variance of Phenotypic Traits
𝜎2T = The observed (phenotypic) variability of a trait
𝜎2T = 𝜎2G + 𝜎2E = The phenotypic variability can be partitioned in to variability due to genetic and environmental effects
𝜎2G = 𝜎2A + 𝜎2D = The genetic component can be further partitioned into additive and dominance genetic variance
We can write a model for the trait as:
T = (A + D) + E = G + E
Additive and Dominance Components
Consider a frequency distribution of trait values for two alleles B and b, where B creates a high trait value and b creates a low trait value on a continuous scale which is shifted so that the midpoint between the mean of BB (+a) and bb (-a) is 0:
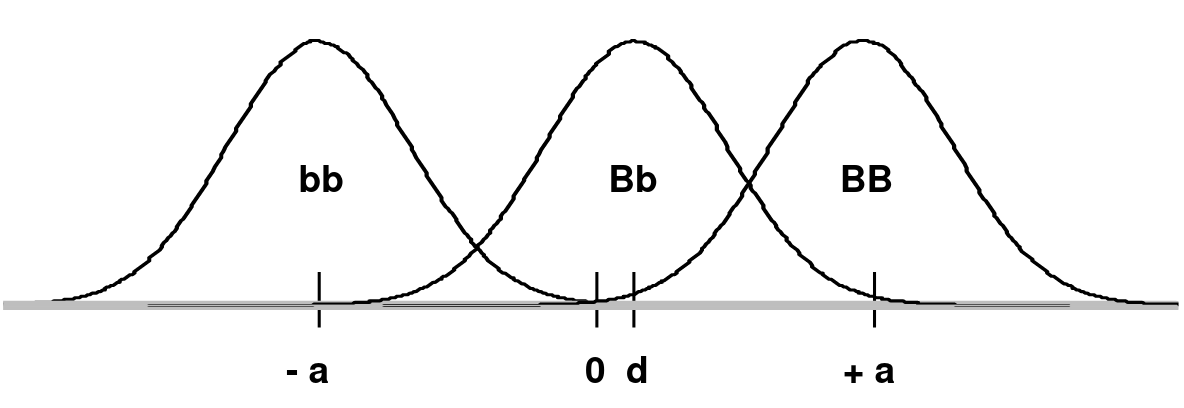
d is the mean of the Bb group
In an additive model d = 0 (no dominance; dominance variance = 0)
In a recessive model: d = -a (Bb would overlap the bb distribution)
In a dominant model d = +a (Bb would overlap the BB distribution)
The degree of dominance can be defined as d/a
Heritability
The heritability of a trait is the proportion of total phenotypic variance that is due to genetic effects.
Heritability can be defined as:
h2 = 𝜎2G / 𝜎2T = ( 𝜎2A + 𝜎2D ) / ( 𝜎2A + 𝜎2D + 𝜎2E )
The above formula is also called Broad sense hertiability. Narrow sense heritability (just the additive component):
hn2 = 𝜎2A / 𝜎2T
We use the expected resemblance among relatives to estimate h2. It is a function of covariance between relatives and coefficient of relationship (AKA "Additive coefficent")
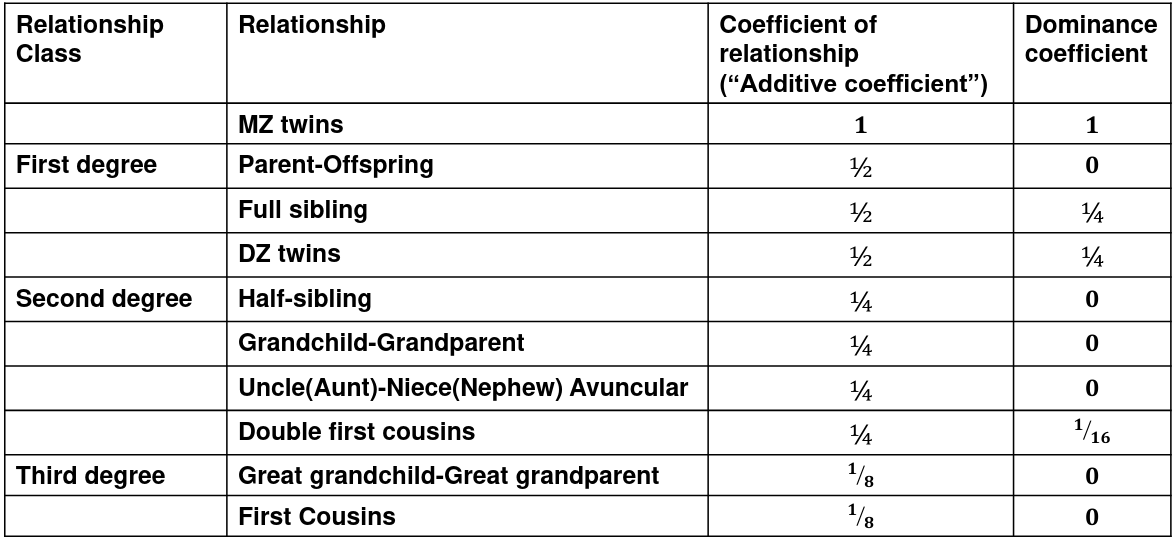
The additive coefficient of a relationship C is the expected proportion of alleles shared IBD by a relative pair, defined as:
C = 2-R, where R is the degree of relationship
- R = 0: MZ twins -> C = 1
- R = 1: 1st degree relationship; sib, parent-offspring -> C = 1/2
- R = 2: 2nd degree relatives: half-sibs, grandparent-grandchild, avuncular
- R = 3: 1st cousins
Recall sharing a allele Identical-By-Descent means relatives who share the exact same copy of an allele by inheritance.
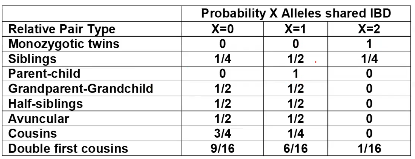
The additive coefficient is expected proportion of alleles shared IBD by the pair, so we can also define it as
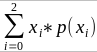
p(x) = x/2 = the proportion of shared alleles
For example, the parent child relationship would have a additive coefficient of 0*(0/2) + 1*(1/2) + 0*(2/2) = 1/2
The kinship coefficient is the probability that a randomly selected pair of alleles from a individual is IBD. It is always half of the coefficent of relationship.
Estimating Heritability
Recall the properties of covariance:
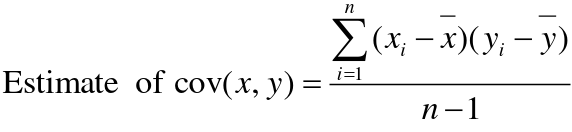
- Cov(X,Y) = Cov(Y,X)
- Cov(X, X) = var(X)
- Cov(X + Y, Z) = Cov(X, Z) + Cov(Y, Z)
- Cov(cX, Y) = c*Cov(X, Y); where c is some constant
- The unit of covariance is xy
- Positive covariance: Value of x tends to be high when value of y is high
- Negative covariance: Value of x tends to be high when value of y is low
A standardized measure of covariance is correlation which is a scale of -1 to 1