Model Fit & Concepts of Interaction
Review of Logistic and Proportional Hazards Regression Model Selection:
You can look at changes in the deviance (-2 log likelihood change)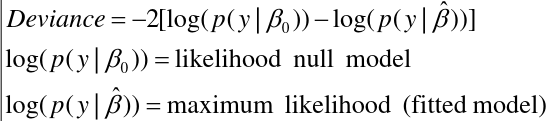
- Deviance - Residual sum of squares with normal data
- Problem: Deviances alone do not penalize "model complexity" (hence need LRT - but only applies to nested models)
- AIC, BIC - More commonly used
- Larger BIC and AIC -> worse model
- BIC is more conservative
- Both based on likelihood
- An advantage is that you do not need hierarchical models to compare the AIC or BIC between models
- A disadvantage is there is no test nor p-value that goes with comparison of models
- A model with smaller values of AIC or BIC provides a better fit
- Used to compare non-nested models
- A non-nested model refers to one that is not nested in another; The set of independent variables in one model is not a subset of the independent variables in the other models
- The data must be the same
Risk Prediction and Model Performance
How well does this model predict whether a person will have the outcome? Generally only for dichotomous outcomes, especially in genetics.
- Calibration - Quantifies how close predictions are to actual outcomes - goodness of fit
- Models for which expected and observed event rates in subgroups are similar are well-calibrated
- Discrimination - The ability of the model to distinguish correctly between the two classes of outcome
Logistic
- A model that assigns a probability of 1 to all events and 0 to non-events would have perfect calibration and discrimination
- A model that assigns a probability of .51 to all events and .49 to all non-events would have perfect discrimination and poor calibration
Hosmer-Lemshow Test
The Hosmer-Lemshow Test is a statistical goodness of fit test for logistic regression models. It is frequently used in risk prediction models. It assesses whether or not the observed event rates match expected event rates in subgroups of the model population of size n. Specifically, it identifies subgroups as the deciles of size nj based on fitted risk values.
H0: The observed and expected proportions are the same across all groups
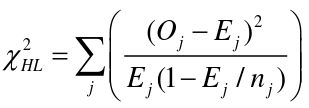
- Oj and Ej refer to the observed events and expected events respective in the jth group
- nj refers to the number of observations in the jth group
- Sensitive to small event probabilities in categories
- Sensitive to large sample sizes
- Problems: Results immensely depend on the number of groups and there is no theory to guide the choice of that number. It cannot be used to compare models.
ROC: Receiver Operating Curve / C Statistic
Plots sensitivity (true positive) for different decisions and look for best trade off between sensitivity and specificity (true negative). The curve is generated using signal detection applications.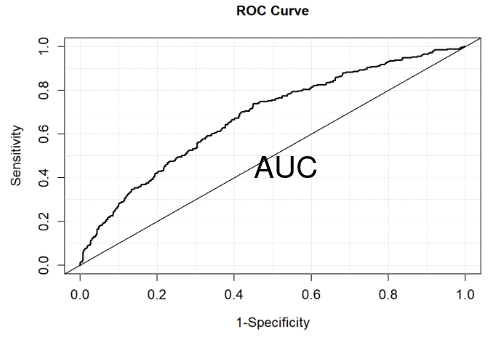
The area under the curve (AUC) is a summary measure called the c statistic, which is the probability that a randomly chosen subject with the event will have a higher predicted probability of the event than a randomly chosen subject without the event (a measure of discrimination).
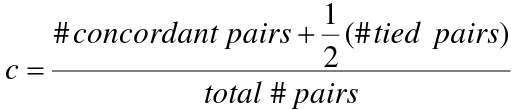
- > .8 - very good
- > .75 - good
- > .7 - acceptable
- > .65 - weak
- > .6 - poor
- < .6 - useless
The c statistic groups all pairs of subjects with different outcomes and identifies pairs where the subject with the higher predicted value also has the higher outcome concordantly. Pairs where the subject with the higher predicted value has the lower outcome are discordant.
When we use the c-statistic in the data used to build the model it cannot be interpreted as the "true" predictive accuracy. It is simply a measure of goodness of fit.
Real predictive accuracy can be estimated when you have a new data set that is not used to generate the model. If that is not possible, inter-validation can be considered:
- Random split - Random splitting of the sample into training and validation many times (100+)
- Cross-validation - Dividing the sample into k sub-samples and train the model on k-1 samples then validate on the remaining sample and repeat many times
- Bootstrap - Resampling with replacement a new version of your sample, where each observation has the same probability of selection. The new sample is used for analysis many times
Survival Analysis
- Calibration at large - compares how close the mean of the model-based predicted probabilities at time t is to the Kaplan-Meier estimate at time t
- Calibration by decile - replace rates/proportions in deciles with their Kaplan-Meier equivalents; change degrees of freedom to 9
- c-statistic has several extensions to survival data, the most popular is Harrell's:
- Call any two subjects comparable if we can tell which one survived longer
- Call two subjects concordant if they are comparable and their predicted probabilities of survival agree with their observed survival times
- 'c' defined as the probability of concordance given comparability
Interaction Analysis
R Code
library(effects) # To plot interactions
library(survival) # load survival package
# Hosmer-Lemshow Test
mod <- glm(y~x, family=binomial)
hl <- hoslem.test(mod$y, fitted(mod), g = 10)